Automated Face Detection for Pre-modern Japanese Artworks using Deep Neural Networks
Alexis Mermet
Ecole Polytechnique Fédérale de Lausanne (EPFL) National Institute of Informatics (NII)
Asanobu Kitamoto
ROIS-DS Center for Open Data in the Humanities National Institute of Informatics (NII)
Chikahiko Suzuki
ROIS-DS Center for Open Data in the Humanities National Institute of Informatics (NII)
Akira Takagishi
University of Tokyo
Introduction
In art history research, comparative style study, based on the visual comparison of characteristics in artworks, is a typical approach to answering research questions about works, such as the identification of creators, the period of production, and the skill of the painter. The creation of dataset useful for such tasks is a complicated and time consuming process for art historians. The motivation of this paper is to help creating such collection by allowing efficient interaction between humans and computers. To achieve this goal, we are using machine learning based solutions, more particularly, object detection, classification and neural networks visualization methods. An useful starting point for such work is the KaoKore dataset[1]. This collection consists of high quality, manually annotated, facial expressions from pre-modern Japanese picture scrolls and picture books.
Methods
The creation of a dataset like KaoKore consists of two steps; namely the detection step and the interpretation step. The detection step involves identifying the location of a face object, while the interpretation step involves identifying the meaning of a face object, such as gender, position, status, and orientation of the face. To automate this process, we need a face detector for the first step, and a face classifier for the second one. For both of these tasks, our challenge is in the size of the fully annotated dataset, which is usually much smaller than expected for training a deep learning-based detector and classifier. This problem is caused not only by the limited availability of open Japanese artwork images, but also by the cost of manual annotation for a large number of artworks. Thus, our machine learning algorithms should learn from small dataset and help human annotators to reduce the cost of annotation.
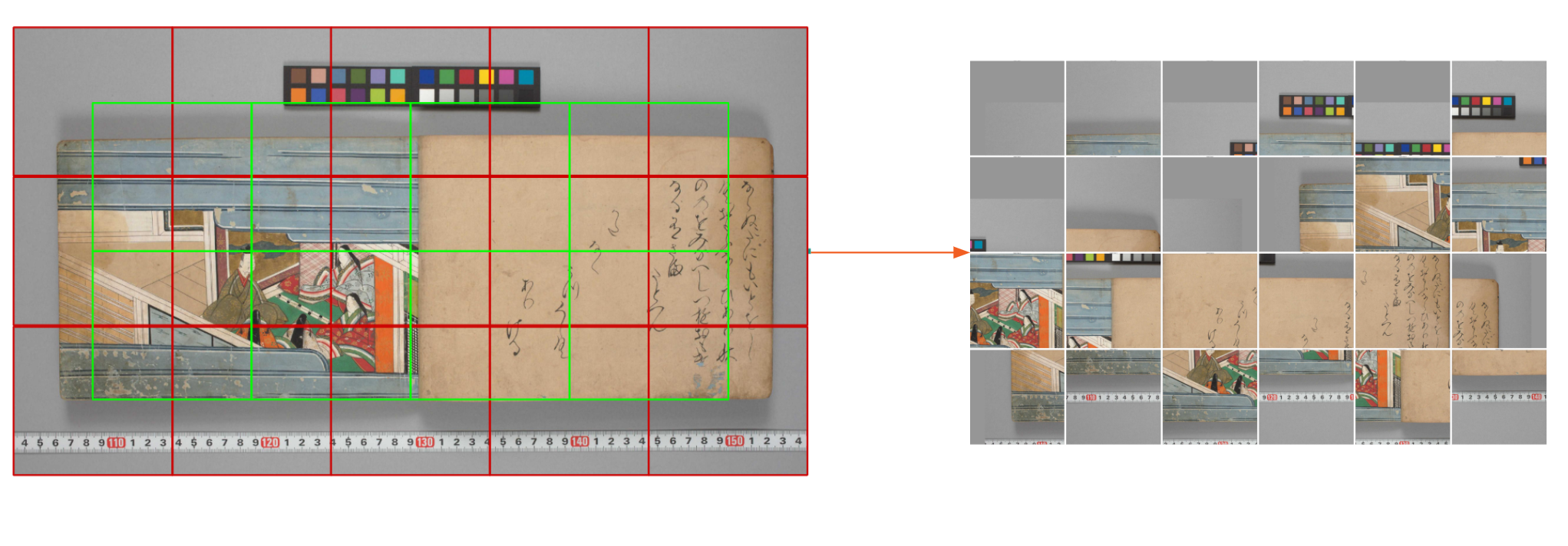
Our technical contribution for the first task is in employing a patching approach, that we called image patching, to solve the problem of small-scale and large-size image datasets. Taking inspiration from research on style detection [2, 3] we implemented a detector using patches of variable sizes that can be used as inputs for multiple deep learning architectures[4, 5, 6, 7]. The patching approach consists of the following (see figure 1): after padding an image to a required size, we crop sub-images of a desired size from it, These sub-images, that we call patches, can either contain faces bounding boxes or not. Please refer to [8] for the detail of the algorithm.
Fig. 1: Creation of patches of size 600*600 to input an SSD 300 backbone on an image from the Kaokore collection
The image patching method has the advantage of minimizing the loss of detail induced by the resizing process that occurs before entering any deep learning architecture. Using architectures with input layer of large enough dimensions, the patches created by the image patching approach are of the same dimension as the input layer. Otherwise, when the detector’s input dimensions are too small, the patches obtained with image patching can be easily resized to the dimension expected by the detector while minimizing the loss of detail and preserving the patch’s aspect ratios. This approach also allows to extend the dataset by multiplying the number of artworks and faces that can be used while training the detector.
For the second task of interpretation, we trained a classifier for the status of the face (see Section Results). Moreover, to study graphical features of faces in pre-modern Japanese artworks, we combined Guided Backpropagation algorithm[9] and the Grad-CAM algorithm[10] to keep track of the propagation of an object’s gradient through a network and highlighted which pixels of the object triggered positive activation in the classifier.
Results
We first describe dataset split and evaluation metric that needs to be defined before experiments. The dataset split concerns how to divide the dataset into a training and testing sets. In addition to a typical approach called random split, we employed new approaches called inter-books split and intra-books split to take correlations within books/scrolls into consideration [8]. In the intrabooks split, for example, each book/scroll should have its images in both the training and testing sets so that machine learning algorithms can learn from all books/scrolls in the dataset. On the other hand, evaluation metric is defined as follows.
Recall is the number of properly detected faces among all the faces that should have been detected.
Precision is the number of properly detected faces among all the faces that have been detected.
Mean Average Precision, abridged to mAP, is a measure falling between 0 and 1 used to compute the accuracy of an object detector at a given level. This level corresponds to the threshold at which we consider that a predicted bounding box and a target bounding box are overlapping or not.
For the detection step, we tried many combinations of deep learning models, and the result indicates that a Faster R-CNN architecture[6], pretrained on ImageNet[11] and setup on ResNet50[7], and patches of size 1333 * 800 is our best face detector on pre-modern Japanese artworks, with a MaP score of 82.9% and a Recall of 91.1% on the Kaokore dataset. The same deep learning architecture without patches only achieved a MaP score of 79.0% and a Recall of 89.7% 89.7%. This suggests that the patching approach is effective for training a face detector.
For the interpretation step, we trained a ResNext[12] classifier to predict the status of any face. This classifier attained an accuracy of 85.009% on all classes. It achieves high classification score on the Nobles, Warriors and Monks class while having an hard time to classify Commoners, showing that some status must have graphical representation rules while other don’t. It also allowed to highlight relevant features for status classification, such as the ears, the hairstyles, the eyes and the hats.
Finally, to test the utility of our face detector in a realistic setup, we applied the detector to a completely new images from Japanese painting scrolls, ‘Yugyo Shonin Engi-Emaki Shojo-Kouji Kouhon’, archived in Shojo-Kouji Temple, Japan (hereafter we call it Kouhon dataset). Without any additional training, the detector obtained the list of bounding boxes for faces from Kouhon dataset, as shown in Figure 2, and the results were then used by art historians for complete annotation. Our approach reached a precision of 84.17% and a recall of 64.65% 64.65%. This result suggests that the total cost of the detection step is reduced to only around 1/3 of its original cost in comparison to completely manual annotation.
Conclusion and future works
The most encouraging result is that the proposed face detector worked effective even for images from new books (Kouhon dataset) without tuning parameters. This result suggests that our face detector can be used for expanding the horizon of research through the cycle of dataset expansion and model re-training for updating parameters. In the future, we could improve our existing method for detection or even automatize the whole annotation procedure including detection and interpretation. The interpretation task could be sped up by a classifier so that art historians only have to care about hard cases that the network is not able to interpret.
Fig. 2: Detection example on the Kouhon dataset using our best performing network (using patches). Image courtesy of Shojo-Kouji Temple.
Acknowledgment
Special appreciation goes to Shojo-Kouji and Yugyoji Museum for allowing us to use the Kouhon dataset for collaborative research.
References
[1] Y. Tian, C. Suzuki, T. Clanuwat, M. Bober-Irizar, A. Lamb, and A. Kitamoto, “Kaokore: A pre-modern japanese art facial expression dataset,” 2020.
[2] C. Sandoval, E. Pirogova, and M. Lech, “Two-stage deep learning approach to the classification of fine-art paintings,” IEEE Access, vol. 7, pp. 41770–41781, 2019.
[3] R. Bai, H. Ling, Z. Kai, D. Qi, and Q. Wang, “Author recognition of fineart paintings,” in 2019 Chinese Control Conference (CCC), pp. 8513–8518, 2019.
[4] Z. Cai and N. Vasconcelos, “Cascade r-cnn: Delving into high quality object detection,” 2017.
[5] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y. Fu, and A. C. Berg, “Ssd: Single shot multibox detector,” Lecture Notes in Computer Science, p. 21–37, 2016.
[6] S. Ren, K. He, R. Girshick, and J. Sun, “Faster r-cnn: Towards real-time object detection with region proposal networks,” 2015.
[7] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” 2014.
[8] A. Mermet, A. Kitamoto, C. Suzuki, and A. Takagishi, “Face detection on pre-modern japanese artworks using r-cnn and image patching for semiautomatic annotation,” in SUMAC 2020 - 2nd Workshop on Structuring and Understanding of Multimedia heritAge Contents, in press.
[9] J. T. Springenberg, A. Dosovitskiy, T. Brox, and M. Riedmiller, “Striving for simplicity: The all convolutional net,” 2014.
[10] R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra, “Grad-cam: Visual explanations from deep networks via gradientbased localization,” International Journal of Computer Vision, vol. 128, p. 336–359, Oct 2019.
[11] J. Deng, W. Dong, R. Socher, L. Li, Kai Li, and Li Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in 2009 IEEE Conference on Computer Vision and Pattern Recognition, pp. 248–255, 2009.
[12] S. Xie, R. Girshick, P. Dollár, Z. Tu, and K. He, “Aggregated residual transformations for deep neural networks,” 2016.