Thomas Leyh
University of Freiburg
National Institute of Informatics
Asanobu Kitamoto
ROIS-DS Center for Open Data in the Humanities
National Institute of Informatics
Thomas Leyh
University of Freiburg
National Institute of Informatics
Asanobu Kitamoto
ROIS-DS Center for Open Data in the Humanities
National Institute of Informatics
Digital Humanities have potential to reduce the complexity of bibliographical study by developing technical tools to support comparison of books. So far, the effort has been mainly put into text-based methods on large corpora of literary text. However, the emergence of large image datasets, along with the recent progress in computer vision, opens up new possibilities for bibliographical study without text transcriptions. This paper describes the technical development of such an approach to Japanese pre-modern text, and in particular to Bukan, which is a special type of Japanese woodblock-printed book.
The authors have been approaching this problem in the past (KITAMOTO et al. 2018). They proposed the concept of “differential reading” for visual comparison. Furthermore, (Invernizzi 2019) proposed “visual named-entity recognition” for identifying family crests, using them for a page-by-page matching across different versions. This paper is a follow-up of these works and proposes a keypoint-based method for the page-by-page matching, additionally yielding an option for highlighting differences.
This work is mainly concerned with extracting information from a specific type of book: 武鑑—Bukan. These are historic Japanese books from the Edo period (1603-1868). Serving as unofficial directories of people in Tokugawa Bakufu (the ruling government in Japan), they include a wealth of information about regional characteristics such as persons, families and other key factors. See figure 1 for an example. These books were created with woodblock-printing. Because the same woodblock has been reused for many versions of the book—sometimes with minor modifications—visual comparison can reveal which part of the woodblock was modified or has degraded.

ROIS-DS Center for Open Data in the Humanities and the National Institute of Japanese Literature are offering 381 of these Bukan as open data (Center for Open Data in the Humanities 2018). The original images have a width of 5616 and height of 3744 pixels. From the open data we created a derived dataset using the following preprocessing methods. Under the assumption that this task (1) does not require this level of detail, (2) does not require information about color and (3) only compares the actual pages, not the surrounding area, all scans are resized by 25%, converted to grayscale and finally cropped, resulting in an image shape of 990 × 660 pixels. If there are two book pages per scan, they are split at their horizontal center, yielding a shape of 495 × 660 pixels per page.
Using an approach based on Computer Vision, two techniques were applied:
Keypoint Detection and Matching for finding the same features in different images.
Projective Transformations for comparing two different images regardless of their original orientation.
We used the OpenCV software library (Bradski 2000).
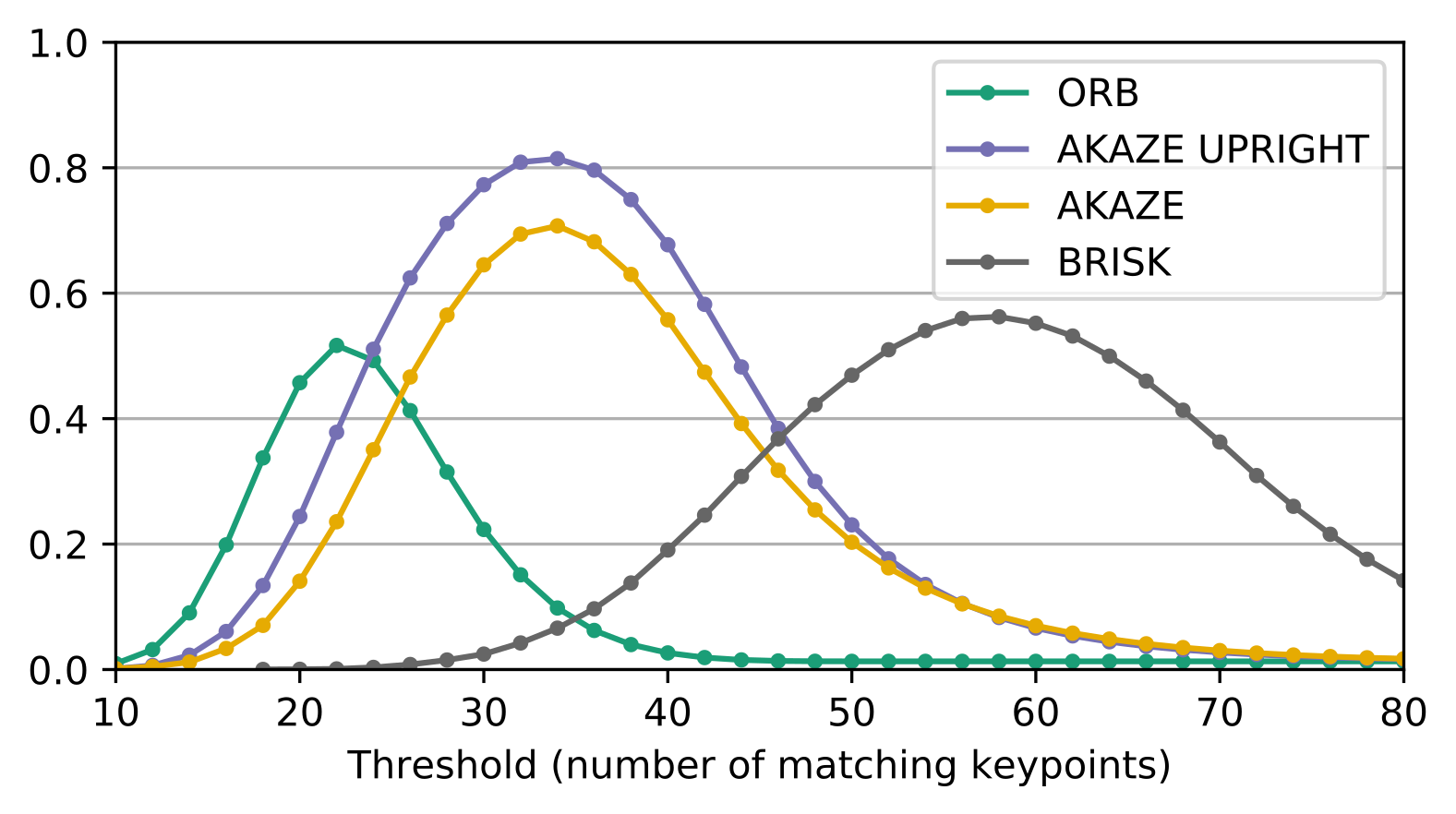
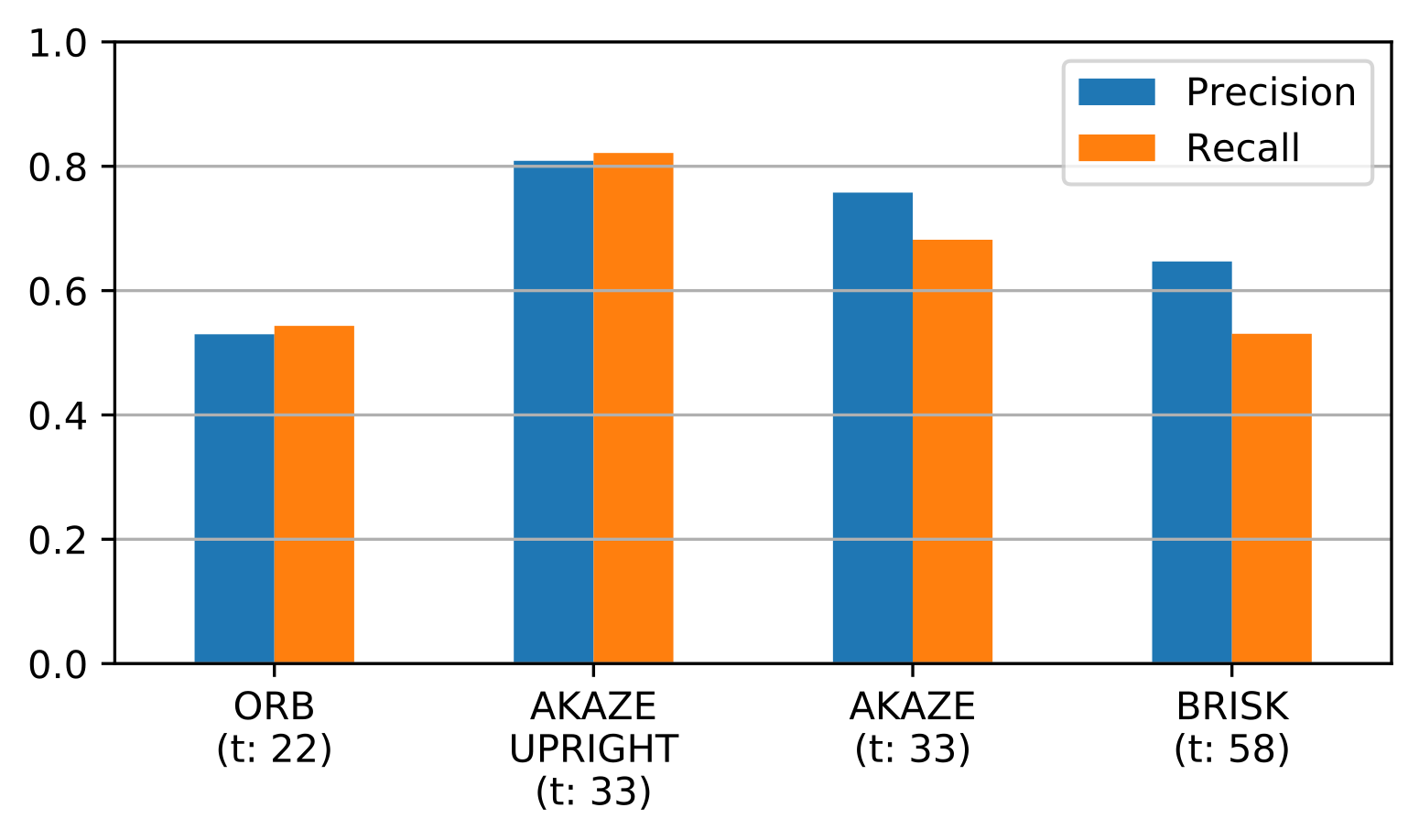
Fig. 2: Evaluation of the performance of four keypoint detection algorithms. AKAZE UPRIGHT performs best.
Keypoint Detection (Szeliski 2010, Ch.4) is about finding points of interest in an image that are most noticeable and give a unique description of the local area surrounding them. Computer Vision research produced various kinds of keypoints, most prominently SIFT (Lowe 2004). For evaluating the performance of these algorithms, 12 prints of the Shūchin Bukan (袖珍武鑑) were manually annotated, in total around 1800 pages, holding information about pairs of matching pages.
Using these annotations, six keypoint algorithms were empirically evaluated1 by trying to match over all possible page combinations. This produces a list of similar keypoint pairs for each combination. The number of these pairs is interpreted as score for the similarity of two pages. Two pages are matched if the score is above a given threshold. On the one hand, a low threshold results in more matches (higher recall), but a larger part is judged incorrectly. On the other hand, a high threshold yields a larger percentage of correct matches (higher precision), misclassifying actual matches at the same time. Using the annotations, precision and recall were calculated for a range of thresholds. At this point, AKAZE UPRIGHT has the best performance with both metrics around 0.8 for an optimal threshold value. See figure 2 for further details.
Projective Transformation (or Homography) for images is defined as a matrix H ∈ R3 × 3 for transforming homogeneous coordinates Hx⃗ = y⃗ (x⃗ and y⃗ are interpolated pixel coordinates). This operation results in linear transformations like translation and rotation, but also changes in perspective (Marschner and Shirley 2015). For finding such a transformation from matching keypoints, the heuristic Random Sample Consensus (RANSAC) algorithm is commonly used (Fischler and Bolles 1981). Basically, a random subset of matching keypoints is chosen, using this to compute a transformation and calculating an error metric. By iteratively using different random subsets, eventually the transformation with the smallest error is picked.
The benefit is twofold: First, the algorithm implicitly uses spatial information of the matching image candidates to filter out false positives, thus greatly boosting the matching performance. Precision and recall are close to their maximum of 1.0, see figure 3. Secondly, it directly yields the transformation matrix H, enabling the creation of image overlays for visualizing the differences. Looking at the perspective components of H, additional filtering is done2, removing even more of the remaining false positives.
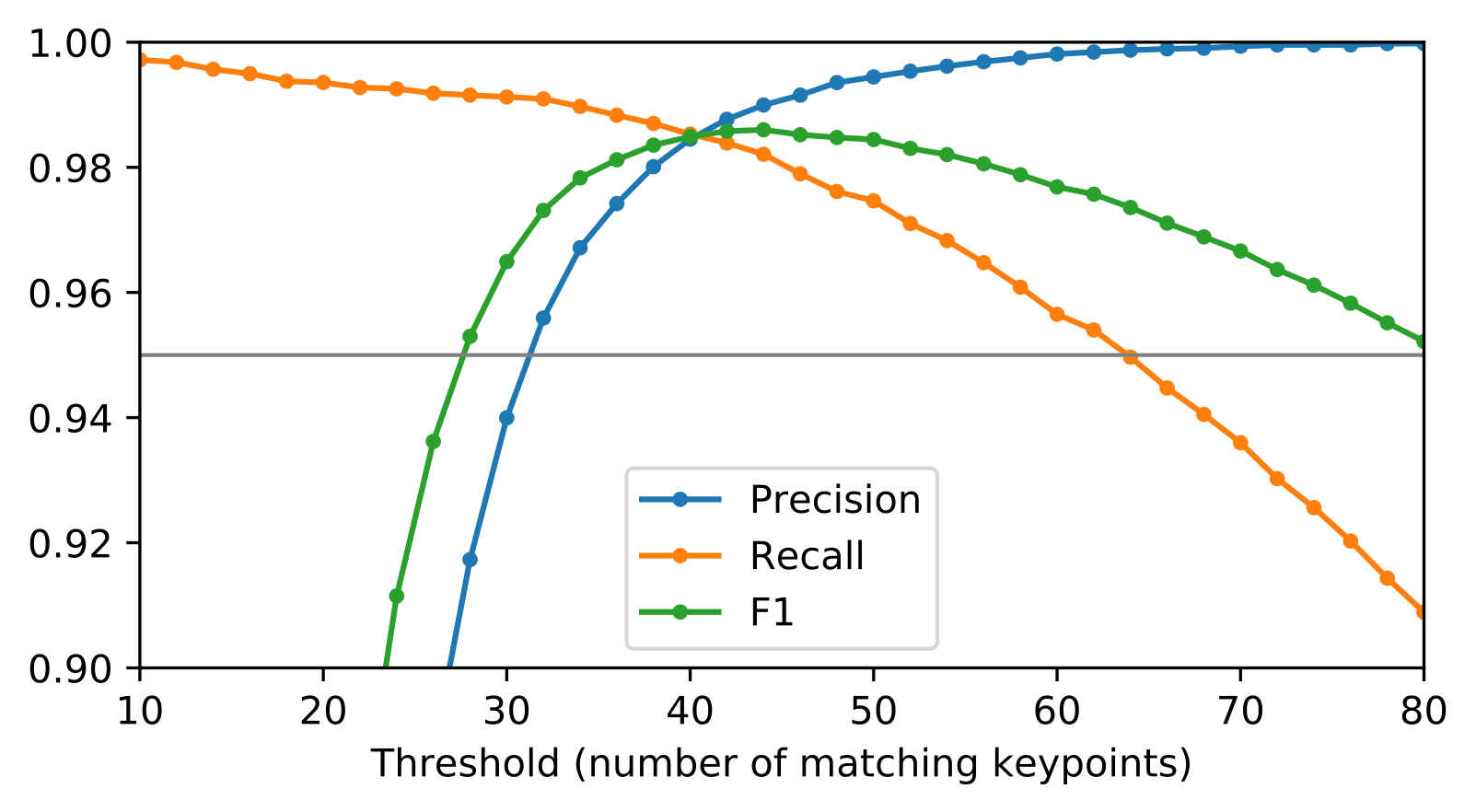
This two-step-pipeline archives high precision and recall when looking for similar pages of different book editions. Performance seems to be robust with respect to most parameters. For matching two actual pages, the number of matching keypoints is important since it is acting as a score. Storing this value allows a ranking of page pairs by visual similarity. Furthermore, a threshold can be set dynamically, even after the computation of keypoint pairs. Assuming semi-automatic application with a human assessing the results, recall is of higher importance, thus a low threshold of around 40 is recommended, but can be adjusted any time. See again figure 3 for the slope of the recall curve.
This was the basis for building a web-based prototype of a comparison browser: A scholar in the humanities can browse a book while getting information about similar pages. Differences between pages can be visualized at any time, similar to figure 4. As a next step, we are designing a web-based tool that is easy to use and works for IIIF images.
Prof. Kumiko Fujizane, who is a Japanese humanities scholar specialized in this particular type of books and collaborates with us, says that the major strength of our method is in identifying differences which are hard to discern by human eye, while its weakness is in errors caused by the distortion of pages by the book binding. Her request for future work is to identify region-based difference in addition to page-based difference.

The proposed method has wide applicability in woodblock-printed books, because the method uses only visual characteristics obtained from computer vision, and does not depend on the content nor the text of books. Although image alignment is a mature research area we also see recent developments, such as RANSAC-Flow (Shen et al. 2020), with potential to improve our results.
Alcantarilla, Pablo F, and T Solutions. 2011. “Fast Explicit Diffusion for Accelerated Features in Nonlinear Scale Spaces.” IEEE Trans. Patt. Anal. Mach. Intell 34 (7): 1281–98. https://doi.org/10.5244/C.27.13.
Bay, Herbert, Tinne Tuytelaars, and Luc Van Gool. 2006. “Surf: Speeded up Robust Features.” In European Conference on Computer Vision, 404–17. Springer. https://doi.org/10.1007/11744023_32.
Bradski, G. 2000. “The OpenCV Library.” Dr. Dobb’s Journal of Software Tools.
Center for Open Data in the Humanities. 2018. “武鑑全集とは?.” July 28, 2018. http://codh.rois.ac.jp/bukan/about/.
Fischler, Martin A, and Robert C Bolles. 1981. “Random Sample Consensus: A Paradigm for Model Fitting with Applications to Image Analysis and Automated Cartography.” Communications of the ACM 24 (6): 381–95. https://doi.org/10.1145/358669.358692.
Invernizzi, Hakim. 2019. “An Iconography-Based Approach to Named Entities Indexing in Digitized Book Collections.” Master’s thesis, École polytechnique fédérale de Lausanne.
KITAMOTO, Asanobu, Hiroshi HORII, Misato HORII, Chikahiko SUZUKI, Kazuaki YAMAMOTO, and Kumiko FUJIZANE. 2018. “Differential Reading by Image-Based Change Detection and Prospect for Human-Machine Collaboration for Differential Transcription.” In Digital Humanities 2018.
Leutenegger, Stefan, Margarita Chli, and Roland Y Siegwart. 2011. “BRISK: Binary Robust Invariant Scalable Keypoints.” In 2011 International Conference on Computer Vision, 2548–55. Ieee. https://doi.org/10.1109/ICCV.2011.6126542.
Lowe, David G. 2004. “Distinctive Image Features from Scale-Invariant Keypoints.” International Journal of Computer Vision 60 (2): 91–110. https://doi.org/10.1023/B:VISI.0000029664.99615.94.
Marschner, Steve, and Peter Shirley. 2015. Fundamentals of Computer Graphics. CRC Press.
Rublee, E., V. Rabaud, K. Konolige, and G. Bradski. 2011. “ORB: An Efficient Alternative to Sift or Surf.” In 2011 International Conference on Computer Vision, 2564–71. https://doi.org/10.1109/ICCV.2011.6126544.
Shen, Xi, Francois Darmon, Alexei A Efros, and Mathieu Aubry. 2020. “RANSAC-Flow: Generic Two-Stage Image Alignment.” In ArXiv.
Szeliski, R. 2010. Computer Vision: Algorithms and Applications. Texts in Computer Science. Springer London.