Iku Fujita
Graduate School of Language and Culture, Osaka University
Iku Fujita
Graduate School of Language and Culture, Osaka University
This research aims to investigate the characteristic use of modal adverbs in Alfred Tennyson’s works. A number of studies on Tennyson’s poems have paid critical attention to stylistic similarities between Tennyson and other poets (Jordan, 1988; Ricks, 1987; Shaw, 1976; Ricks, 1969; to name but a few). As Leech (1969: 13) states, “[L]iterary archaism is often inspired by the wish to follow the model of a particular writer or school of writers of the past,” it can readily be imagined that authors follow the way that remarkable forerunners had written, namely, their styles. However, having stylistic similarities does not necessarily mean reflecting literary artistry/quality.
Currently, the digital humanities approach is contributing to literary studies. (e.g. Hori, 2019; Tabata, 2016; Mahlberg and McIntyre, 2011). Poetry is no exception and this process is now bringing new, additional knowledge to previous poetry studies from different aspects (e.g. Tartakovsky and Shen, 2019; Nakao and Jimura, 2016).
The study identifies characteristic modal adverbs in Tennyson’s works in comparison to the Augustan, Romantic, and Victorian poetry composed by Pope, Byron, Keats, Shelley, Browning, Coleridge, Wordsworth, Swinburne, D. Rossetti, Arnold, and Southey. Words under investigation include belike, haply, maybe, mayhap, peradventure, perchance, perhaps, and possibly as modal adverbs, which mainly express epistemic possibility or uncertainty (Quirk et al., 1985; Greenbaum, 1969; Poutsma, 1928). The adoption of these poets is based on Shaw (1976), which indicates that there are resemblances in the styles between Tennyson and these authors. Four authors have been added to obtain more comprehensive results. The frequencies of eight modal adverbs are listed below in Table 1.
Table 1. Frequencies of eight modal adverbs for the 12 authors1

Correspondence analysis (CA) is useful in visualizing hidden relationships between variables, namely the authors and modal adverbs in this paper. As Tabata (2004: 112) demonstrates, CA is an effective method, in the case when data contains low-frequency content words as variables for stylistic investigation. Tabata (2005) is one such study that sheds light on the advantages of CA: “CA is one of the techniques for data-reduction alongside PCA and FA. Unlike PCA and FA, however, CA does not require the intervening steps of calculating a correlation matrix or a covariance matrix, and can, therefore, process the data directly to obtain a solution” (Tabata, 2005: 68).
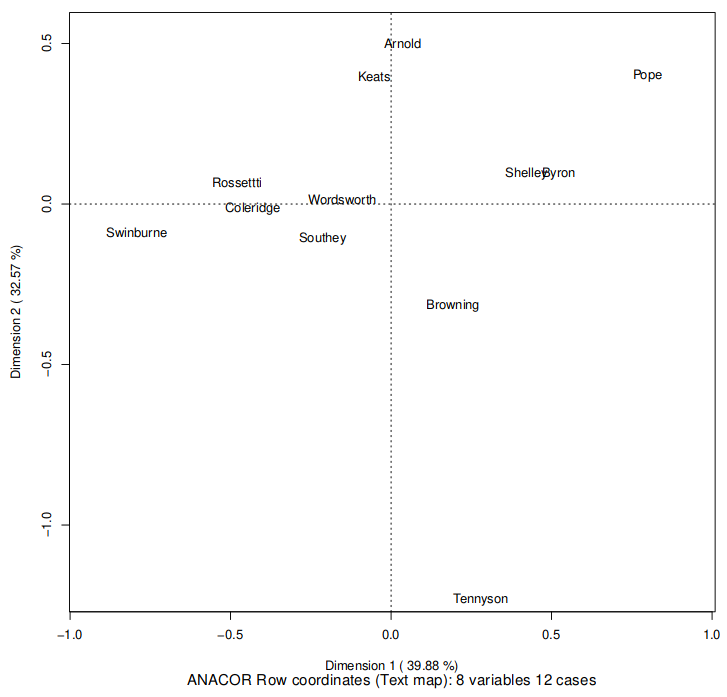
A result of CA shows Tennyson as an outliner in Fig 1. While the other 11 authors are located between -0.5 and 0.5 along the vertical axis, Tennyson locates alone at the bottom of the plot. In this plot, relative distance between data points reflects similarity or contrast.
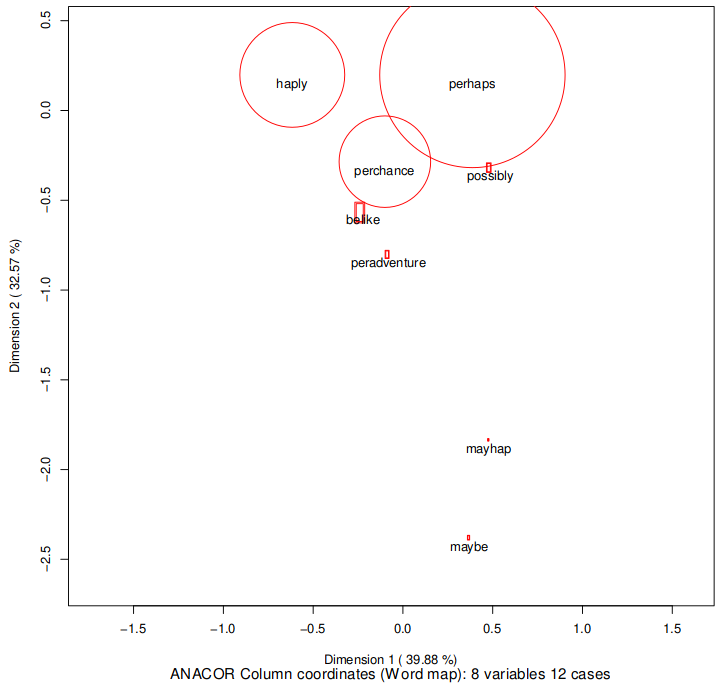
The column plot indicates that the variables maybe and mayhap are outliners (Fig 2). Again, their proximity explains the similarity of their frequency patterns between variables: the closer data points are located each other, the greater similarity they have between them in the frequency patterns of modal adverbs. Additionally, the radius of the circle indicates the relative frequency of the word. Although the circle of maybe and mayhap are not larger than any other variables, these two adverbs deviate from the other six adverbs.
In addition to the result of CA, the Mann-Whitney’s U test (MW test) was conducted to find significant frequency differences between Tennyson and the control authors. The MW test is a nonparametric method which tests the variance of the medians. The test needs two independent groups as samples; therefore, in this study, Tennyson is set as the target group (64 works), and the others are set as the control group (926 works). Table 2 shows the result of MW test. The MW test result shows that haply, mayhap, and maybe are statistically significant (p-value < 0.01). The effect sizes are all quite small, and thus there is a room for improvement, this paper will consider the reason(s) of why these two adverbs stand out in Tennyson’s works. Given the result of CA and MW test, mayhap and maybe can be listed as characteristic modal adverbs in Tennyson.
Table 2. The result of MW test

*: p < 0.01
Turning our attention to each work of authors, mayhap appears in Browning, Southey and Tennyson’s works. In Tennyson, however, mayhap is used only his Lincolnshire dialectal poetry so that mayhap can make the sound of his dialect in his poetry.
The OED (online) records first quotation of maybe dated in 1400. It mentions that maybe was popularly used by writers in the seventeenth century; but, was not a standard word before the mid-nineteenth century (s.v. maybe, adv., n., and adj.). In the case of Tennyson, the first maybe appeared in 1842. The duration of time when Tennyson started to use maybe and the time when the OED refers to maybe is quite short. Among the 12 authors, only three Victorian poets used maybe, and none of the Augustan nor Romantic poets used the word. This is in keeping with the description of the OED. One of the motives of its usage is presumably the aforementioned “literature archaism” (Leech, 1969: 13). Moreover, maybe and mayhap behave differently, compared to the other six modal adverbs. These do not collocate with other modal auxiliaries such as may, might, or can. That could be a repercussion of authors’ lexical choices as it led to differences in their prosody.
This study limits its discussion to eight modal adverbs in Tennyson’s poems; however, we can also see some of the poet’s stylistic features. This paper investigates the use of modal adverbs through quantitative analysis, yet qualitative analysis will be essential in future research.
The author would like to thank the anonymous reviewers for the constructive feedback.
Greenbaum, S. (1969). Studies in English Adverbial Usage. Florida: University of Miami Press.
Hori, M. (2019). “Itsudatsu-shita Collocation-to Idiom: Dickens-no The Pickwick Papers-no Baai (Deviation of Collocations and Idioms: In case of Dickens’s The Pickwick Papers).” Gengo Bunseki-no Frontier, 2019. pp. 308-321.
Jordan, E. (1988). Alfred Tennyson. Cambridge: Cambridge University Press.
Leech, N. G. (1969). A Linguistic Guide to English Poetry. London and New York: Longman.
Mahlberg, M. and McIntyre, D. (2011). “A case for corpus stylistics: Ian Fleming’s Casino Royale.” English Text Construction 4:2. pp. 204-227.
Nakao, Y. and Jimura, A. (2016). The Canterbury Tales-no Shahon-to Kanhon-ni okeru Gengo-to Buntai-ni tsuite (The language and style of the manuscripts and printed books of the Canterbury Tales.) Hori, Masahiro. (ed.) Tokyo: Hituzi Syobou. pp. 21-52.
Poutsma, H. (1928). A Grammar of Late Modern English. 2nd ed. Groningen: P. Noordhoff.
Quirk, R., Greenbaum, S., Leech, G. and Starvik, J. (1985). A Comprehensive Grammar of the English Language. London and New York: Longman.
Ricks, C. (1969). The Poems of Tennyson. (ed.) London: Longman.
_____. (1987). The Poems of Tennyson in Three Volumes. (ed.) London: Longman.
Shaw, W. D. (1976). Tennyson’s Style. Ithaca and London: Cornell University Press.
Tabata, T. (2004). “—ly fukushi-no Seikihinndo Kaiseki-niyoru Bunntai Shikibetu: Koresupondensu Bunnseki-to Syuseibunn Bunnseki -niyoru Hikaku Kennkyuu (Style Identification of -ly adverbs by the occurrence frequencies: Comparing the correspondence analysis and principal component analysis.” Denshika Gengo Shiryou Bunseki Kenkyu, 2003. pp. 97-114.
_____. (2005). “Stylistics of --ly adverbs in Dickens and Smollet: A quantitative study by means of correspondence” Denshika Gengo Shiryou Bunseki Kenkyu, 2004-2005. pp. 65-78.
_____. (2016). Kyoucho Sakuhin-ni okeru Dickens-no Buntai (The Style of Dickens in Cowritten Works.) Hori, Masahiro. (ed.) Tokyo: Hituzi Syobou. pp. 53-71.
Tartakovsky, R. and Yehsyahu, S. (2019). “Meek as milk and large as logic: A corpus study of the non-standard poetic simile.” Language and Literature, 2019, vol.28, No. 3. pp. 203-220.
The Oxford English Dictionary (online): https://www.oed.com/ (the last access date: 2020-9-28)
Frequencies are normalized per million words↩︎